How We Built a 3B Model That Beats GPT-5.4 at Tuvaluan — And What It Can't Do Yet
A technical deep dive into two-stage training, synthetic data bootstrapping, and why the hardest eval is a children's book.

Code & data: github.com/G-structure/tuvalu-llm | Live model: tuvalugpt.tv/chat | Dataset: HuggingFace
The Setup
Tuvalu has 11,000 speakers, nine coral atolls, and roughly 15 years before sea level rise makes most of the country uninhabitable. Tuvaluan has no presence in any frontier AI system. Google Translate doesn't support it. GPT-5.4 hallucinates when you ask it to translate. Claude apologizes and tries anyway. Gemini just gives you Samoan.
We set out to build a model that actually works for Tuvaluan. Not as a demo — as a real system that native speakers would use. The constraint was brutal: there is almost no digitized Tuvaluan text on the internet.
We entered the SemiAnalysis hackathon at NVIDIA GTC 2026, placed 3rd, and won a DGX Spark. Our 3B-active model (Qwen3-30B-A3B, MoE) beat GPT-5.4 on 6 of 7 Tuvaluan task slices. But the story of how we got there — and where it breaks — is more interesting than the leaderboard position.
TL;DR
We built the largest Tuvaluan-English parallel corpus ever assembled (342k raw pairs), then ran a two-stage training pipeline:
- Stage A: LoRA fine-tune on the base model for translation only. Purpose: produce a high-quality translator we can use as a tool.
- Stage B: Use Stage A to translate English capability datasets (chat, QA, math, summarization, code, tool-use) into Tuvaluan. Then train a new LoRA adapter from the chat model on a mix of English, synthetic Tuvaluan, cross-lingual, and anchor translation data.
The result: a bilingual Tuvaluan assistant that translates, chats, answers questions, and summarizes — all in a language that frontier models can't handle.
The catch: on truly held-out data (a children's book the model has never seen), we score chrF++ 47.1 en→tvl — barely ahead of GPT-5.4's 45.5. And going tvl→en, GPT-5.4 beats us. Good enough to be useful. Not good enough to be trusted without review.
Step 1: Building the Corpus
There is no Common Crawl dump for Tuvaluan. No Wikipedia. No parallel corpus on OPUS. We had to build everything from scratch.
Sources
| Source | Type | Method |
|---|---|---|
| JW WOL Bible | Verse-aligned TVL/EN | Scraped all 66 books, verse-level alignment |
| JW WOL Articles | Paragraph-aligned | Bilingual articles, paragraph-matched by docId |
| JW Daily Text | Date-aligned | Daily devotional pages |
| Tuvalu Dictionary | Word/expression pairs | Full dictionary from tuvalu.aa-ken.jp, ~3,200 entries |
| Tuvalu Learning App | Vocabulary + expressions | 23 expression categories + 42 word lists |
| OCR Scanned PDFs | Unstructured text | Tuvalu News Sheets, "The Magical Garlands of Nukufetau" |
| Bilingual PDFs | Extracted pairs | Government and educational documents |
All scraping used Docker curl-impersonate for browser-like TLS fingerprints. Not glamorous work, but it's the foundation.
Cleaning
Raw scraping gave us 667,875 aligned pairs. After cleaning, we kept 182,713. The rejection rate was 72%.
The cleaning pipeline (tv/corpus/clean.py) runs: Unicode NFC normalization, invisible character stripping, HTML entity replacement, scripture reference removal, glottal stop normalization (all variants mapped to U+2035 reversed prime), dictionary-guided macron correction, boilerplate detection, deduplication by content hash, and length ratio filtering.
Bible data dominates the corpus. To prevent the model from speaking exclusively in scripture, we capped Bible at 70% of training data and applied aggressive deduplication.
Rendering Training Examples
Each accepted pair gets rendered in BOTH directions (tvl→en and en→tvl), using 3 template variants per direction selected deterministically by hash. Dictionary entries get specialized vocabulary templates. Bible holdout uses Ruth, Philemon, and Jude as test books; Obadiah, 2 John, and 3 John for validation.
Final training set: 377,122 rendered examples, ~74.6M tokens.
Step 2: Stage A — The Translation Adapter
Stage A has one job: learn to translate between Tuvaluan and English well enough that we can use it as a synthetic data generator.
Config
- Base model:
Qwen/Qwen3-30B-A3B-Base(30B total params, 3B active — Mixture of Experts) - Method: LoRA, rank 32
- Sequence length: 2048
- Batch size: 64
- Learning rate: 2e-4, linear decay
- Epochs: 3
- Platform: Thinking Machines' Tinker stack
We explored Llama-3.2-3B as a Stage A pilot first (LoRA rank 16, smaller batch). It worked but Qwen3-30B-A3B was substantially better — the MoE architecture lets you get 30B-class capacity at 3B inference cost.
Stage A Results
| Direction | chrF++ | BLEU |
|---|---|---|
| en → tvl | 68.2 | 49.9 |
| tvl → en | 59.9 | 42.1 |
| Overall | 64.5 | 46.7 |
Parse success rate: 99.5%. The model reliably produces well-formed translations. This is the tool we'll use to generate synthetic data.
Step 3: Synthetic Data — Bootstrapping Capabilities
This is the key insight of the whole pipeline: Stage A exists only to make Stage B possible.
We can't train a general-purpose Tuvaluan assistant directly because there's no Tuvaluan chat data, no Tuvaluan QA datasets, no Tuvaluan math problems. But we have great English capability datasets. So we translate them.
The Translation Pipeline
We took 8 English datasets and ran them through Stage A's translator:
| Dataset | Task | Budget Weight |
|---|---|---|
| UltraChat 200k | Chat | 25% |
| TaskSource Instruct | Chat | 15% |
| TinyStories | Chat | 13% |
| CNN/DailyMail | Summarization | 12% |
| xLAM Function Calling | Tool use | 15% |
| GSM8K | Math | 10% |
| SQuAD | QA | 10% |
| MBPP | Code | 10% |
Total budget: 200M tokens. Temperature 0.3 for diversity without drift.
Selective Translation
Not everything should be translated. Code blocks, JSON, URLs, file paths, LaTeX, XML, template variables, shell commands, function signatures, money amounts — these must survive intact.
Our selective translation pipeline (tv/training/synthetic/selective_translate.py) classifies each message as "translate", "preserve", or "selective". Tool-role messages are always preserved. System prompts with tool schemas are preserved. For selective messages, machine-parseable content gets masked with __PH_NNN__ placeholders before translation, then restored after.
Quality Validation
Every translated conversation goes through structural integrity checks:
- Same message count, same roles as original
- No leaked placeholders
- Code blocks byte-identical to source
- JSON still valid
- Length ratio between 0.3x and 3.0x of original
Accept rate: 99.9% on TinyStories (the first dataset through the pipeline).
Cross-Lingual Data
We also built a cross-lingual dataset: English user messages paired with Tuvaluan assistant responses. The user writes in English with an instruction like "Respond in Tuvaluan" (8 variants), and the model responds in Tuvaluan.
This teaches the model to code-switch naturally, which is how real Tuvaluan speakers actually communicate — mixing English and Tuvaluan fluidly.
Step 4: Stage B — The Bilingual Assistant
Here's a critical design decision: Stage B trains from the base model, not from Stage A weights.
Stage A is a specialist translator. We don't want Stage B to inherit its narrow behavior. Instead, we train a fresh LoRA adapter on the chat variant (Qwen/Qwen3-30B-A3B, not -Base) using a carefully balanced mix:
Training Mix
| Source | Share | Examples | Description |
|---|---|---|---|
| English | 30% | 579,211 | Original English capability data |
| Synthetic TVL | 30% | 514,803 | Stage A translations of English data |
| Cross-lingual | 20% | 514,945 | English user → Tuvaluan response |
| Anchor | 20% | 334,870 | Original parallel translation pairs |
Total: 1,943,829 training examples, ~500M tokens.
The anchor data is critical — it's the real parallel corpus from Stage A training. Without it, the model's translation quality degrades because the synthetic data has errors that compound.
Config
- Base model:
Qwen/Qwen3-30B-A3B(chat variant) - Method: LoRA, rank 32
- Batch size: 128
- Learning rate: 2.83e-4
- Epochs: 3
- Train on: LAST_ASSISTANT_MESSAGE
- Task families: chat, tool, math, code, QA, summarization, translation
We also explored openai/gpt-oss-120b for Stage B (LoRA rank 32, batch 32, max_length 4096). More capacity, but the Qwen MoE architecture won on efficiency — we need this model to run on a DGX Spark in Tuvalu, not a datacenter.
Step 5: Evaluation
The Benchmark
We evaluate on 7 task slices with ~500K tokens per model:
| Task Slice | Examples | Description |
|---|---|---|
| translation_en_to_tvl | 250 | Standard translation pairs |
| translation_tvl_to_en | 250 | Standard translation pairs |
| textbook_en_to_tvl | 46 | Held-out children's books |
| textbook_tvl_to_en | 46 | Held-out children's books |
| chat_tvl | 250 | Tuvaluan conversation |
| qa_tvl | 120 | Question-answering in Tuvaluan |
| summarization_tvl | 40 | Tuvaluan text summarization |
Metrics: chrF++ (sacrebleu, word_order=2) as primary, BLEU as secondary.
Cross-Model Results (Shared Benchmark Subset)
On the 28-example shared benchmark subset that all models can be compared on:
| Model | chrF++ |
|---|---|
| TVL Stage B (ours) | 41.8 |
| GPT-5.4 | 36.1 |
| Claude Sonnet 4.6 | 34.2 |
| Google Translate | 29.5 |
| Qwen3-30B (base) | 13.7 |
| Gemini 3.1 Pro | 11.6 |
We lead on 6 of 7 task slices. The one we lose is summarization — frontier models have seen orders of magnitude more summarization training data.
The Textbook Eval (The One That Matters)
The textbook slice is the most honest eval we have. It consists of children's books and museum activity sheets that were never in any training data — not in the parallel corpus, not in the synthetic data, not in any form.
To make this concrete, we ran a head-to-head comparison on a single, complete children's book: The Gifts of Pai and Vau (Meaalofa a Pai mo Vau), a 12-paragraph Nanumean legend published by Reading Warrior. The full book is a bilingual Tuvaluan/English text — we use the English as source and the Tuvaluan as reference, then ask each model to translate. Read the full bilingual book (PDF).
English → Tuvaluan (the hard direction)
| Model | chrF++ | BLEU |
|---|---|---|
| TVL Stage B (ours) | 47.1 | 18.5 |
| GPT-5.4 | 45.5 | 18.8 |
| Claude Sonnet 4.6 | 37.3 | 11.8 |
| GPT-5.4 Nano | 32.3 | 5.9 |
We lead, but narrowly. GPT-5.4 is surprisingly close at 45.5 — OpenAI has clearly improved its Polynesian language coverage since we started this project. Claude and Nano trail significantly.
Tuvaluan → English (where frontier models have the advantage)
| Model | chrF++ | BLEU |
|---|---|---|
| GPT-5.4 | 51.5 | 26.8 |
| Claude Sonnet 4.6 | 48.8 | 24.8 |
| TVL Stage B (ours) | 42.4 | 19.6 |
| GPT-5.4 Nano | 40.2 | 15.4 |
Here GPT-5.4 wins convincingly. This makes sense: translating from a low-resource language to English is easier for frontier models because they understand English extremely well. They just need to pattern-match enough Tuvaluan to get the gist. Our model's advantage — deep Tuvaluan knowledge — matters more going the other direction.
Side-by-Side: What the Translations Actually Look Like
Source (English): "Once there were two women, called Pai and Vau, who owned baskets of magical sand. They poured some of the sand into the ocean, where it formed an island. They named the island, Na Mea, which means, This Place. Later, it became Nanumea. 'This place will be a blessing to future generations,' they said."
Reference (Tuvaluan): "Nateaho e iai he tokolua fafine, e igoa kia Pai mo Vau, kae e iai ni laa kete one fakataulaaitu. Ni 'ligi ni la one ki te moana, tela ni tupu ake iai he fenua. Ni fakaigoa e laaua te fenua kia, Na Mea, tona uiga, Momea Nei. Mai tua ifo ni fakaigoa kia Nanumea. 'Momea nei e fakamanuiagina moo kautama ateaho,' munaa laaua."
TVL Stage B: "E isi ne fāfine e tokolua, ko Pai mo Vau, kolā e isi ne lā pōla o one fakataulaitu. Ne ‵ligi ne lāua a nāi one ki te moana, kae ne fakatu aka i ei se fenua. Ne fakaigoa ne lāua te fenua tenā ki a Na Mea..."
GPT-5.4: "I aso mua ne tokolua fafine, e fakaigoa ki a Pai mo Vau, kolā ne maua ne lāua a kato one fakamaneta. Ne lilingi ne lāua a nisi o te one ki loto i te tai..."
GPT-5.4 Nano: "E iai aso muamuamua ni fafine se toalua, e igoa ia Pai ma Vau, oe sa umia ni pakete o le oneone faamaneta. Sa latou sasaa sina oneone i totonu o le sami..." ← This is Samoan, not Tuvaluan.
Claude Sonnet 4.6: "I tasi aso ne i ai ni fafine e lua, ko Pai mo Vau, nā umiti ni kete one fakamanogi..."
Key observations:
- Our model produces recognizable Tuvaluan with correct particles and structure, though some vocabulary differs from the Nanumean dialect of the reference
- GPT-5.4 produces plausible Tuvaluan but uses some non-Tuvaluan vocabulary ("fakamaneta" for magical, "kato" for basket)
- GPT-5.4 Nano produces Samoan, not Tuvaluan — confirming that smaller frontier models have no Tuvaluan capability at all
- Claude uses a mix of Tuvaluan and other Polynesian language features
The Bible Contamination Problem (Caught in Real-Time)
The most revealing failure shows up in paragraph 3 (tvl→en direction). The source text describes Tefolaha finding footprints ("kalofaga") in the sand. Our model's translation:
"So Job went on to see the tracks of the wild ass. He did not follow the hares, and he came to the house of the Tuʹman·ites..."
The model confused "kalofaga" (footprints) with Bible vocabulary and hallucinated a passage about Job. This is the Bible contamination problem in action: when the model encounters an uncommon Tuvaluan word, it falls back to the most frequent training domain — scripture. GPT-5.4, which has no Bible fine-tuning, correctly translates the same passage as "Tefolaha found a kalofaga on the beach."
This is exactly the kind of failure that chrF++ averages hide. The overall score looks competitive, but individual paragraphs can be catastrophically wrong in ways that betray the training data distribution.
You can reproduce these results yourself:
scripts/compare_textbook_models.py. Requires an OpenRouter API key. Full prediction outputs are saved toeval/textbook_comparison/.
What chrF++ 47.1 Means in Practice
A chrF++ of 47.1 on genuinely held-out children's books means the model produces recognizable Tuvaluan that a native speaker can follow. It does NOT mean the translations are safe to ship without human review. We see consistent issues:
- Vocabulary gaps: Words that appear only in children's literature and not in our Bible/article-heavy corpus
- Register mismatch: The model defaults to a slightly formal tone (Bible influence) when the source is casual children's language
- Dialect variation: The reference uses Nanumean Tuvaluan; our model produces a more generic/mixed dialect
- Compound sentence structure: Long Tuvaluan sentences with multiple clauses often get restructured incorrectly
Full Per-Slice Breakdown (Stage B)
| Task Slice | chrF++ | BLEU |
|---|---|---|
| translation_en_to_tvl | 59.7 | 41.9 |
| translation_tvl_to_en | 61.3 | 43.6 |
| textbook_en_to_tvl | 41.5 | 11.8 |
| textbook_tvl_to_en | 34.9 | 17.0 |
| chat_tvl | 28.2 | 9.8 |
| qa_tvl | 31.8 | 16.5 |
| summarization_tvl | 35.5 | 13.7 |
Notice the gap between translation (chrF++ ~60) and everything else (28-42). Translation is where we have the most real data. Chat, QA, and summarization rely heavily on synthetic data, and it shows.
Collapse Detection
When you deploy a small model for production translation (we translate football articles daily from Goal.com, FIFA, and Sky Sports), you hit a failure mode that benchmarks don't capture: model collapse.
The model starts repeating n-grams in a degenerate loop. A 200-word article becomes 800 words of the same phrase repeated 40 times. This happens unpredictably and is catastrophic for user trust.
Our collapse detector (scripts/detect_collapse.py) combines 6 signals:
- Whole-text n-gram uniqueness: Ratio of unique 4-grams to total. Below 30% → collapsed.
- Max n-gram frequency: Any single 4-gram > 40% of total → collapsed.
- Tail collapse: Last 80 words checked for repetition spirals.
- Sliding window: Every 100-word window (stride 50) checked individually.
- Repeated long phrases: Any 5-8 word phrase appearing 8+ times.
- Per-paragraph: Individual paragraph repetition check.
The translation pipeline retries with escalating temperature (0.0 → 0.3 → 0.7) when collapse is detected. All attempts — collapsed or not — are recorded in a translation_attempts table for future RL training data.
What Doesn't Work Yet (Honestly)
1. The Corpus Is Religiously Biased
~60% of our parallel data comes from JW WOL (Bible + religious articles). Despite downsampling, the model has a measurable bias toward formal, scriptural register. When a football article says "the crowd erupted," our model sometimes produces something closer to "the multitude raised their voices." We cap Bible at 70% in training, but the influence persists.
2. Synthetic Data Compounds Errors
Stage A makes translation errors. When those errors propagate into Stage B's training data, Stage B learns them as ground truth. We see this most clearly in tool-use tasks: the selective translation pipeline preserves JSON and code, but surrounding Tuvaluan context sometimes has grammatical errors that Stage A introduced.
We don't yet have a way to automatically detect these cascaded errors. Native speaker review is the only reliable filter, and it doesn't scale.
3. Chat Quality Lags Translation Quality
chrF++ 28.2 on chat vs 60.5 on translation. The gap is real. Our model can translate a paragraph accurately, but ask it to have a natural conversation in Tuvaluan and it produces awkward, stilted responses. The synthetic chat data helps but isn't a substitute for real conversational Tuvaluan data — which essentially doesn't exist in digital form.
4. The Textbook Ceiling
chrF++ 47.1 on the Pai & Vau book and GPT-5.4 at 45.5 right behind us. That's a 1.6-point lead on en→tvl — not a moat. And on tvl→en, GPT-5.4 beats us by 9 points (51.5 vs 42.4). The Bible contamination hallucination (translating "footprints" as "Job and the wild ass") is the kind of failure that destroys user trust in a single paragraph, regardless of aggregate scores. Getting from 47 to 60+ on truly out-of-domain text requires much more diverse training data, dialect-aware training, and probably native speaker post-training.
5. Collapse Under Load
Model collapse in production is manageable with retry logic, but it shouldn't happen at all. We see collapse rates of ~5-8% on first attempts for longer articles. The temperature escalation (0.0 → 0.3 → 0.7) resolves most cases, but it triples inference cost for affected articles.
What's Next
Feedback Loop
The football news app (futipolo.tv) is live and collecting paragraph-level feedback from Tuvaluan readers: thumbs up/down, corrections, reading mode preferences, island-tagged participation. This is the data we need to close the quality gap — real speakers telling us what sounds right and what doesn't.
The signals feed into a preference dataset we plan to use for DPO/RLHF-style post-training. Every collapsed translation and its retry attempts are stored as training pairs: the model's outputs ranked by native speaker feedback.
More Diverse Data
We need non-religious Tuvaluan text at scale. Government documents, community newsletters, social media, song lyrics, oral history transcriptions. Most of this exists on paper or in people's memories, not on the internet. Digitization partnerships with Tuvaluan institutions are the path forward.
Hardware Deployment
The DGX Spark is going to Tuvalu. Running inference on-island means the community doesn't depend on our cloud infrastructure. True sovereignty requires local compute.
Infrastructure: Thinking Machines' Tinker
All training ran on Thinking Machines' Tinker platform. Tinker provides managed LoRA fine-tuning with checkpoint storage, generation evaluation during training, and inference serving — all accessible via a Python SDK.
We trained both Stage A and Stage B as LoRA adapters (rank 32) through Tinker's training API. Checkpoints are stored as tinker:// URIs and can be served immediately for inference. Generation eval runs in parallel during training with 64 concurrent requests, so we can monitor translation quality without stopping the training run.
For a project with zero ML infrastructure budget, this was essential. We could iterate on training configs, run evals, and serve the model for production translation all from the same platform.
What This Actually Cost
We get asked this a lot: "how much compute does it take to beat GPT-5.4 at a language?" Here's the honest answer.
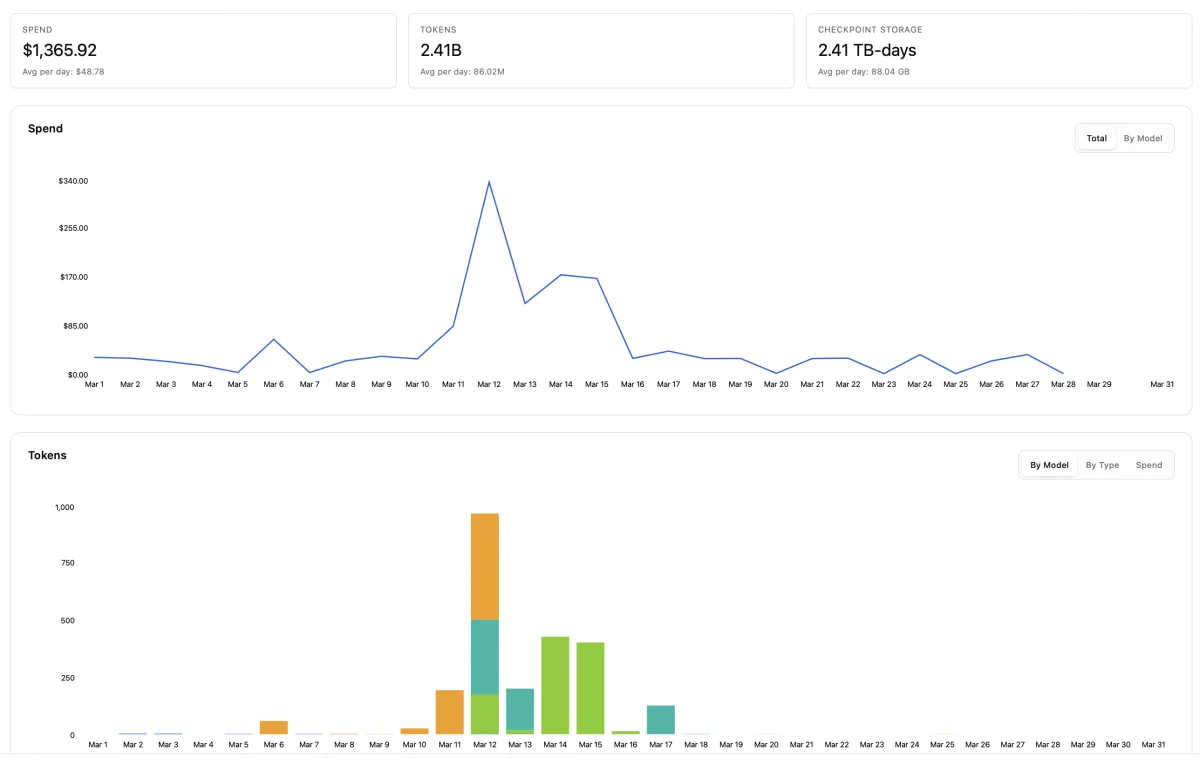
Our full Tinker spend for March 2026. Every experiment, every failed run, every eval. $1,365.92 total.
$1,365.92. That's everything. All of Stage A training, all of Stage B training, synthetic data generation, every checkpoint, every evaluation run, every failed experiment we threw away. 2.41 billion tokens processed. 2.41 TB-days of checkpoint storage. One month of work.
That includes a lot of waste — early Llama-3.2-3B pilots we abandoned, training configs we tuned wrong, synthetic data runs we restarted. The actual minimum cost to reproduce the final pipeline is lower.
Cost to Reproduce (Just the Final Pipeline)
Thinking Machines' Tinker prices training on Qwen/Qwen3-30B-A3B at $0.36 per million tokens (train), $0.30/M (sample), and $0.12/M (prefill).
| Step | Tokens | Price/M | Cost |
|---|---|---|---|
| Stage A training (3 epochs) | 74.6M | $0.36 | $26.86 |
| Synthetic data generation (Stage A sampling) | ~200M | $0.30 | $60.00 |
| Stage B training (3 epochs) | 500M | $0.36 | $180.00 |
| Evals + inference | ~50M | $0.30 | $15.00 |
| Total | ~825M | ~$282 |
You could reproduce the entire two-stage pipeline — from raw parallel corpus to deployed bilingual assistant — for under $300 on Tinker. That's the cost of a nice dinner, not a research grant.
What If We Trained a Bigger Model?
The MoE architecture is why this is cheap. Qwen3-30B-A3B has 30B total parameters but only activates 3B during inference. If we'd trained on denser or larger models, the math changes fast:
| Model | Train $/M tokens | Stage B cost (500M tokens) | Full pipeline |
|---|---|---|---|
| Qwen/Qwen3-30B-A3B (ours) | $0.36 | $180 | ~$282 |
| gpt-oss/GPT-OSS-120B | $0.52 | $260 | ~$370 |
| Qwen/Qwen3-235B-Instruct | $2.04 | $1,020 | ~$1,200 |
| moonshot/Kimi-K2 Thinking | $2.93 | $1,465 | ~$1,650 |
| Qwen/Qwen3.5-30TB-A17B | $6.00 | $3,000 | ~$3,200 |
The 235B Instruct model would cost 4x more. Kimi K2 would cost 6x more. And the largest Qwen 3.5 model would blow past $3,000 for Stage B training alone. For a self-funded project, MoE efficiency isn't a nice-to-have — it's the difference between "we can iterate" and "we get one shot."
The Real Cost
The $1,365.92 on Tinker is the compute cost. It doesn't include:
- Months of unpaid scraping, cleaning, and alignment work
- A trip to Tuvalu to build relationships with the community
- The time cost of learning to navigate a language with ~zero digital resources
- Server costs for the live football app and inference endpoint
This entire project is self-funded. No grants. No corporate sponsor. No university affiliation. Just a small team that got unreasonably passionate about a language spoken by 11,000 people on islands that might not exist in 15 years.
If you think this kind of work matters — building open-source AI infrastructure for languages that Big Tech will never prioritize — the Language Lab is a 501(c)(3) nonprofit. We could use the help. What can we say, we just really love Tuvalu.
Thanks
This project exists because of the people and organizations who made it possible.
Thinking Machines — For the Tinker platform. All model training, eval, and inference ran on Tinker. Without managed LoRA fine-tuning accessible to a team of our size, this project wouldn't have gotten past the scraping stage.
SemiAnalysis — For organizing the hackathon at GTC 2026 that pushed us to ship. The compressed timeline (48 hours to build, demo, and defend) forced decisions that turned out to be right: MoE over dense, two-stage over monolithic, product over paper.
FluidStack — For hosting the hackathon infrastructure and GPU compute that made the live demos possible.
NVIDIA — For the DGX Spark. It's going to Tuvalu.
The Tuvaluan community members who reviewed translations, submitted corrections, and told us when the model sounded like a Bible instead of a person. The model is better because of you. It needs to get a lot better still.
This post is part of the Language Lab project — a 501(c)(3) nonprofit building open-source AI infrastructure for endangered languages. If you want to help, join the mailing list or reach out at [email protected].
What next
Try the assistant. Check the results.
Open the live Tuvaluan assistant, inspect the evaluation results, or review the code and data behind the system.